谨以此文祭奠过去三天起起落落的辛酸经历。
序
此间与无数Error碰面,奈何benchmark稍显冷门,任凭我历尽多种方法,于谷歌、百度、必应等知名搜索引擎也寻找无果。在翻阅HiBench的Github Issues时,甚至发现与我相同的问题存在数个月之久无人问津,乃至于后来我写邮件求助亦如石沉大海。幸而我时常有灵光乍现的时刻,总会在经历一遍又一遍的试错后,偶得正确解决方案,最终克服了所有的问题,解决掉所有的Error,成功运行Benchmark,作文以记之。
软件安装
- java 1.8
终端运行$ sudo apt update && sudo apt install openjdk-8-jdk - scala 2.11.8
https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
下载并解压二进制包 - hadoop 2.8.3
http://archive.apache.org/dist/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz
下载并解压二进制包 - spark 2.2.2
https://www.apache.org/dyn/closer.lua/spark/spark-2.2.2/spark-2.2.2-bin-hadoop2.7.tgz
下载并解压二进制包 - zookeeper 3.4.10
https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
下载并解压二进制包 - kafka 2.11-0.8.2.2
https://archive.apache.org/dist/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz
下载并解压二进制包 - maven 3.3.9
终端运行$ sudo apt update && sudo apt install maven - hibench 7.0
https://github.com/intel-hadoop/HiBench
clone下来或者下载解压zip
下载解压到某目录后,设置好路径:
添加
|
|
生效
配置软件
Hadoop
进入文件夹
|
|
单机
配置hadoop-env.sh
|
|
将JAVA_HOME改成正确目录
配置core-site.xml
|
|
修改为:
配置hdfs-site.xml
|
|
修改为:
确保ssh到localhost无需密码
|
|
否则执行:
运行
|
|
在yarn上运行
(这步是需要的,我之前没有执行,导致Hibench一直无法正确运行)
配置mapred-site.xml
|
|
修改为:
配置yarn-site.xml
|
|
修改为:
运行
|
|
Zookeeper
进入文件夹
|
|
创建配置文件
|
|
创建数据存储目录
|
|
配置数据存储目录
|
|
修改dataDir项为
启动
|
|
Kafka
进入文件夹
|
|
创建log目录
|
|
配置server.properties
|
|
修改以下项
运行
注意不要关闭终端
Hibench
Build Hibench
进入Hibench源码目录
这里需要挺长一段时间
Hadoop bench
配置hadoop.conf
|
|
修改
尝试运行Hadoop负载测试
|
|
查看报告
|
|
更详细数据在report/identity/hadoop/bench.logreport/identity/hadoop/monitor.html
Spark bench
配置spark.conf
|
|
修改
尝试运行Spark负载测试
|
|
查看报告
|
|
Spark Streaming bench
配置Kafka
|
|
修改为
运行
数据生成
|
|
这里会跑Hadoop,会占资源
这里开始就会一直发送数据,不要关闭
运行测试
这里注意把终端窗口拉长一些,以便找到Spark WebUI的URL
浏览器打开 http://某ip:4040 即可查看实时负载数据
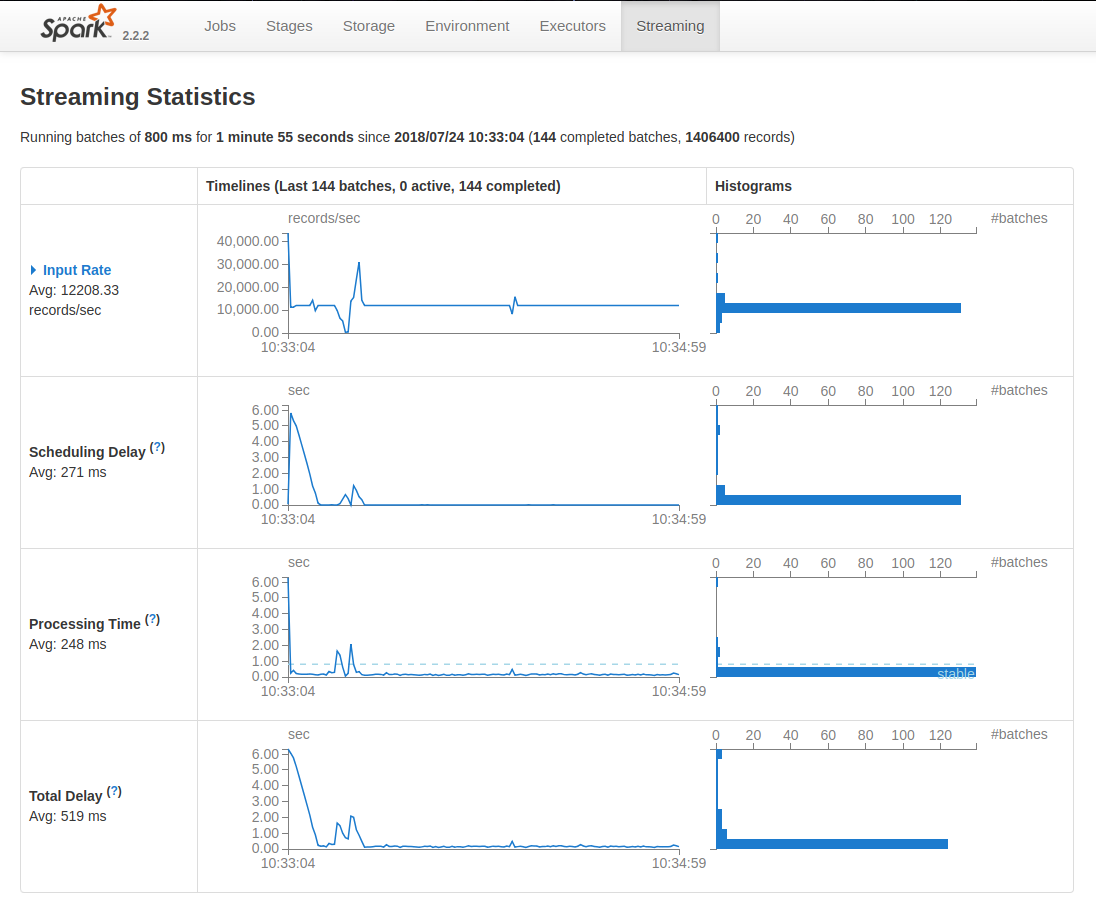
生成报告
|
|
修改负载参数
修改数据量
|
|
|
|
修改spark配置
|
|
|
|
温馨提示
为了避免磁盘被占满,应及时清理kafka和zookeeper产生的数据文件
参考文献
- https://github.com/intel-hadoop/HiBench/blob/master/docs/build-hibench.md
- https://github.com/intel-hadoop/HiBench/blob/master/docs/run-sparkbench.md
- https://github.com/intel-hadoop/HiBench/blob/master/docs/run-streamingbench.md
- http://hadoop.apache.org/docs/r2.8.3/hadoop-project-dist/hadoop-common/SingleCluster.html
- https://zookeeper.apache.org/doc/current/zookeeperStarted.html
- https://kafka.apache.org/quickstart