练习html各元素的获取,熟悉BeautifulSoup的使用。
实例:豆瓣top250电影名单获取。
获取html页面
|
|
User-Agent的获取方法:console敲入命令:navigator.userAgent
解析页面
将html交给BeautifulSoup解析一下
12from bs4 import BeautifulSoupsoup = BeautifulSoup(html, "html.parser")找到数据element
- ol.grid_view
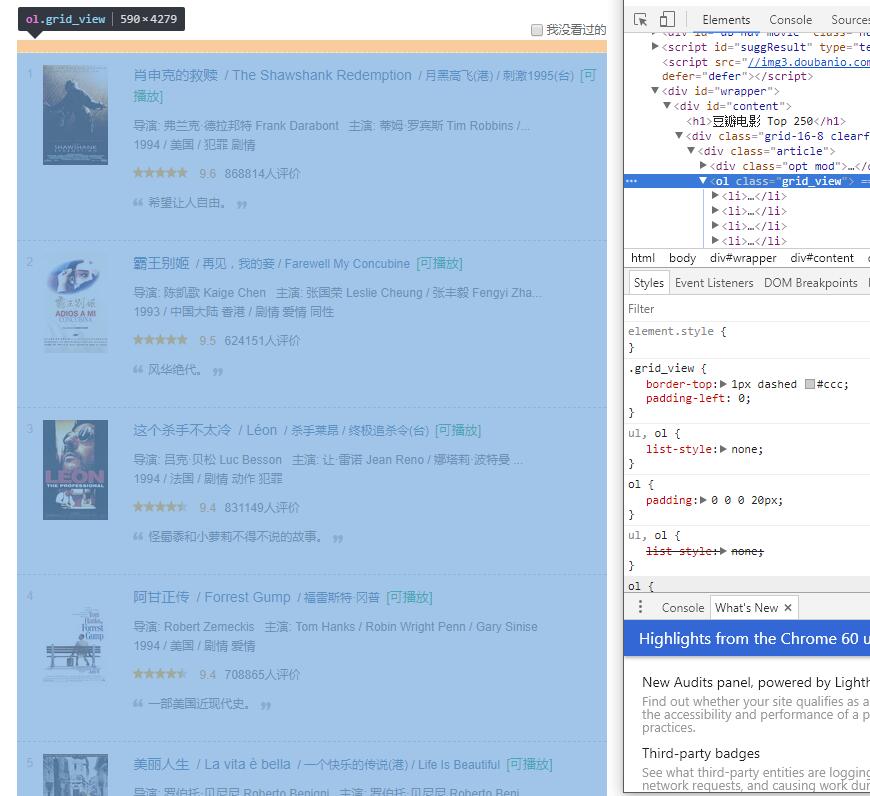
- div.hd

- span.title

出动选择器
123movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})detail = movie_li.find('div', attrs={'class': 'hd'})movie_name = detail.find('span', attrs={'class': 'title'}).getText()循环把一页结果存下来
123456movie_name_list = []for movie_li in movie_list_soup.find_all('li'):detail = movie_li.find('div', attrs={'class': 'hd'})movie_name = detail.find('span', attrs={'class': 'title'}).getText()movie_name_list.append(movie_name)拿到下一页的element
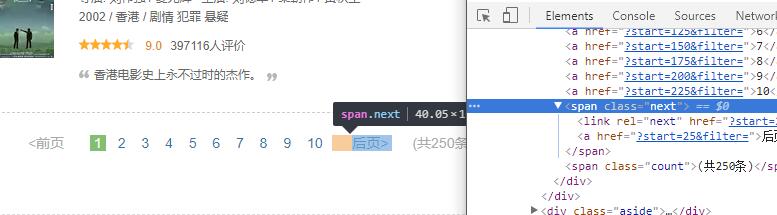 1next_page = soup.find('span', attrs={'class': 'next'}).find('a')
1next_page = soup.find('span', attrs={'class': 'next'}).find('a')
写入文件
|
|
完整代码
|
|