- 2017-10-30
- Java
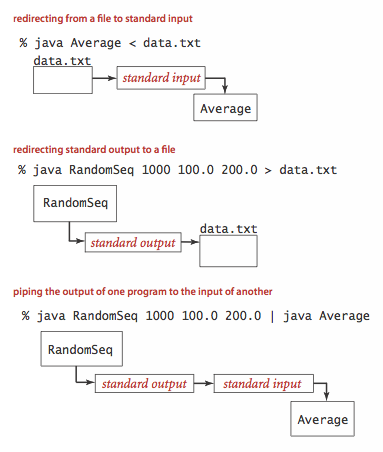
- Redirection and piping.
对于自己创建的每一个类,都考虑置入一个main(),其中包含了用于测试那个类的代码。为使用一个项目中的类,我们没必要删除测试代码。若进行了任何形式的改动,可方便地返回测试。这些代码也可作为如何使用类的一个示例使用。
- Redirection and piping.
- Java
- 2017-10-30
- Java
- Printing strings to the terminal window.

- Converting strings to primitive types.

- Mathematical functions.

- Printing strings to the terminal window.
- Java
- 2017-10-01
- Python
替学委写的自动纠正文件名小程序,被学委嫌弃了。1234567891011121314151617181920212223242526272829303132333435363738394041424344# -*- coding:utf-8 -*-"""将此源码与 name.txt 存放在同一目录下双击运行 prog.py,重命名文件将生成于 new 文件夹中"""import osimport shutildef getMap():lst = []with open("./name.txt", 'r', encoding="utf-8") as f:for line in f:lst.append((line.split("\t")[0], line.split("\t")[2]))f.close()return lstdef changeName(folder, cap):oldDir = foldernewDir = os.path.join(oldDir, "new")if (not os.path.isdir(newDir)):os.mkdir(newDir)nameToId = getMap()for oldFile in os.listdir(oldDir):flag = Falsefor name, no in nameToId:if (oldFile.find(name) != -1):newFile = "计科一班-" + name + "-" + cap + "-" + no + "." + oldFile.split(".")[-1]shutil.copyfile(os.path.join(oldDir, oldFile), os.path.join(newDir, newFile))flag = Trueprint("{:30}\t{} {}".format(oldFile, " 已成功重命名为 ", newFile))breakif (flag == False):if (oldFile != "new"):print("{:30}\t{}".format(oldFile, " 重命名失败!"))def main():folder = input("作业文件夹:")cap = input("请输入章节:")changeName(folder, cap)input("---- 按 Enter 结束程序 ----")main()
- Python
2017-09-16
C
- 12while((ch = getchar()) != EOF)putchar(ch);
结束输入需要手动模拟
EOF,如Ctrl+Z - 1echo_eof < words
把
stdin重定位到words文件。1echo_eof > mywords把
stdout重定位到mywords文件。注:重定位是一个命令行概念。
向函数传入数组,如果对数组并不进行修改操作,建议形式参数使用
const。1234int sum(const int arr[], int n){// something}声明字符串时最好用
char str[],这样str就有了const的感觉。
Python
- 爬取股票信息,包含进度条(进度条在cmd中才能正常显示)1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768import requestsfrom bs4 import BeautifulSoupimport tracebackimport redef getHTMLText(url, code="utf-8"):try:r = requests.get(url,timeout = 30)r.raise_for_status()r.encoding = codereturn r.textexcept:print("404")return ""def getStockList(lst, stockURL):html = getHTMLText(stockURL, "GB2312")soup = BeautifulSoup(html, "html.parser")a = soup.find_all('a')for i in a:try:href = i.attrs["href"]lst.append(re.findall(r"[s][hz]\d{6}", href)[0])except:continuedef getStockInfo(lst, stockURL, fpath):count = 0for stock in lst:url = stockURL + stock + ".html"html = getHTMLText(url)try:if html == "":continueinfoDict = {}soup = BeautifulSoup(html, "html.parser")stockInfo = soup.find("div", attrs={"class":"stock-bets"})name = stockInfo.find_all(attrs={"class":"bets-name"})[0]infoDict.update({"股票名称":name.text.split()[0]})keyList = stockInfo.find_all("dt")valueList = stockInfo.find_all("dd")for i in range(len(keyList)):key = keyList[i].textval = valueList[i].textinfoDict[key] = valwith open(fpath, 'a', encoding="utf-8") as f:f.write(str(infoDict) + '\n')count = count + 1print("\r当前进度:{:.2f}%".format(count*100/len(lst)),end='')except:count = count + 1print("\r当前进度:{:.2f}%".format(count*100/len(lst)),end='')continuedef main():stock_list_url = "http://quote.eastmoney.com/stocklist.html"stock_info_url = "https://gupiao.baidu.com/stock/"output_file = "G://BaiduStockInfo.txt"slist = []getStockList(slist, stock_list_url)getStockInfo(slist, stock_info_url, output_file)main()
- 爬取股票信息,包含进度条(进度条在cmd中才能正常显示)
2017-09-15
C
匿名数组
12int * pt1;pt1 = (int [2]){10, 20};12345int sum(const int arr[], int n);......int total;total = sum((int []){4, 4, 4, 5, 5, 5}, 6);
- 2017-09-09
- JavaScript
atob(),btoa()- 两个函数,作用:不会被一下子看穿秘密
- JavaScript
- 2017-09-08
- Python
淘宝比价爬虫12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152import requestsimport reimport osdef getHTMLTest(url):try:r = requests.get(url,timeout = 30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""def parsePage(ilt, html):try:plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)for i in range(len(plt)):price = eval(plt[i].split(':')[1])title = eval(tlt[i].split(':')[1])ilt.append([price, title])except:print("")def writeGoodsList(ilt):file = "淘宝机械键盘比价.txt"with open(file, 'w') as f:tplt = "{:4}\t{:8}\t{:16}\n"f.write(tplt.format("序号", "价格", "商品名称"))count = 0for g in ilt:count = count + 1f.write(tplt.format(count, g[0], g[1]))f.close()print("文件保存成功")def main():goods = "机械键盘"depth = 5start_url = "https://s.taobao.com/search?q=" + goodsinfoList = []for i in range(depth):try:url = start_url + "&s=" + str(44 * i)html = getHTMLTest(url)parsePage(infoList, html)except:continuewriteGoodsList(infoList)main()
- Python
- 2017-09-05
- 汇编
x86-64中,移位操作对w位长的数据值进行操作,移位量是由%cl寄存器的低m位决定的,这里2^m=w。高位会被忽略。所以,例如当寄存器%cl的十六进制值为0xFF时,指令salb会移7位,salw会移15位,sall会移31位,而salq会移63位。
- 汇编
- 2017-09-02
- Python
帮Karen爬植物志123456789101112131415161718192021222324252627282930313233343536373839404142434445464748import requestsfrom bs4 import BeautifulSoupimport codecsdef getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status()r.encoding = "gbk"return r.textexcept:return "404"def fillPlantList(html):soup = BeautifulSoup(html, "html.parser")plant_name_list = []for tr in soup.find_all("tr", attrs={"bgcolor": "#C1CDDB"}):tds = tr("td")plant_name_list.append(tds[1].string)next_page = Nonefor a in soup.find_all("a", attrs={"class": "bt"}):if (a.text == "下一页"):next_page = aif next_page:return plant_name_list, "http://gjk.scib.ac.cn/gdzwz/" + next_page["href"]else:return plant_name_list, Nonedef main():url = "http://gjk.scib.ac.cn/gdzwz/result.asp"with codecs.open("plant", "wb", encoding="gbk") as fp:while url:html = getHTMLText(url)plant, url = fillPlantList(html)for plant_name in plant:if (plant_name):fp.write(plant_name + '\n')else:fp.write('\n')if __name__ == "__main__":main()
- Python
- 2017-09-01
- Python
- 获取大学排名1234567891011121314151617181920212223242526272829303132333435363738#coding=utf-8import requestsfrom bs4 import BeautifulSoupimport bs4def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""def fillUnivList(ulist, html):soup = BeautifulSoup(html, "html.parser")for tr in soup.find('tbody').children:if isinstance(tr, bs4.element.Tag):tds = tr('td')ulist.append([tds[0].string, tds[1].string, tds[3].string])def printUnivList(ulist, num):tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"print(tplt.format("排名","学校名称","总分",chr(12288)))for i in range(num):u=ulist[i]print(tplt.format(u[0],u[1],u[2],chr(12288)))def main():uinfo = []url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'html = getHTMLText(url)fillUnivList(uinfo, html)printUnivList(uinfo, 100)if __name__ == "__main__":main()
- 获取大学排名
- Python
2017-08-31
- Python
- 获取图片12345678910111213141516171819import requestsimport osurl = "http://image.nationalgeographic.com.cn/2017/0830/20170830031247622.jpg"root = "F://pics//"path = root + url.split('/')[-1]try:if not os.path.exists(root):os.mkdir(root)if not os.path.exists(path):r = requests.get(url)with open(path, 'wb') as f:f.write(r.content)f.close()print("文件保存成功")else:print("文件已存在")except:print("爬取失败")
- 获取图片
- Python
JavaScript
屏蔽
alert()方法1234window.alert = function (a) {console.log(a)return 1}函数别名
1var log = console.log.bind(console)监听键盘按键
12345window.addEventListener('keydown', function(event) {var k = event.keyif (k === '...') {...}})
- 2017-08-30
- C
- 如果在格式字符串中%c之前有一个空格, 那么scanf()会跳到第一个非空白字符处. 即:
scanf("% c", &ch)会读取遇到的第一个非空白字符. - 本人保证输入数据的可靠性的方法,以读取
long数据为例1234567void getlong(long *num){while (scanf("%ld", num) != 1)getchar();while (getchar() != '\n');} // 事后再回显一下
- 如果在格式字符串中%c之前有一个空格, 那么scanf()会跳到第一个非空白字符处. 即:
- C
- 2017-08-28
- JavaScript
- 已绑定到函数参数的值不变
- JSON.stringify(something),将something这个对象序列化成JSON格式,stringify哈哈哈哈哈哈好好笑
- JavaScript