简单笔记
记号数据结构
|
|
例:
“if (x > 5)”
=>
token {k = IF, lexeme = NULL};
// IF 和 “if” 一一对应,没必要记录单词
token {k = LPAREN, lexeme = NULL};
token {k = ID, lexeme = “x”};
…
转移图法
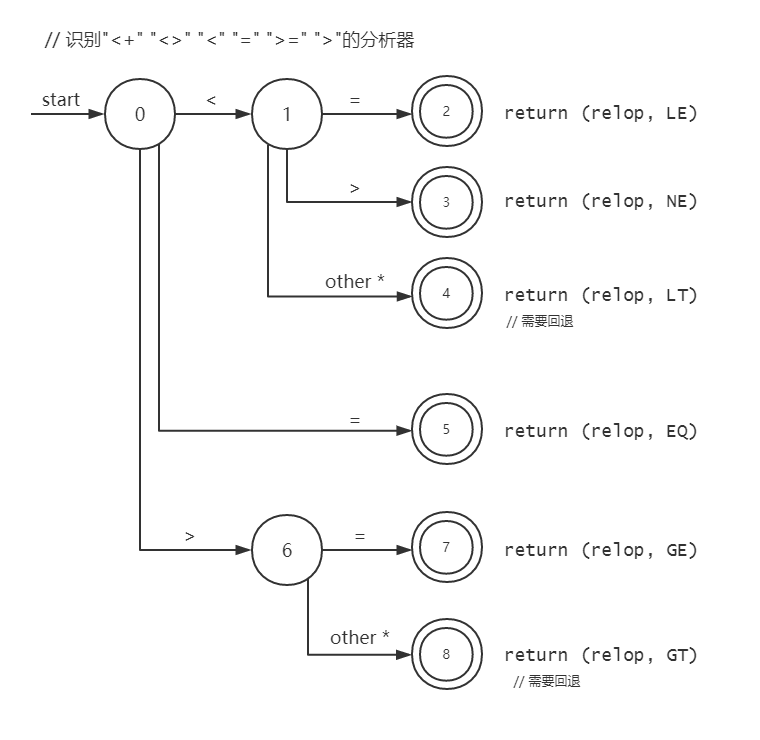
识别比较符
转移图
算法伪代码
|
|
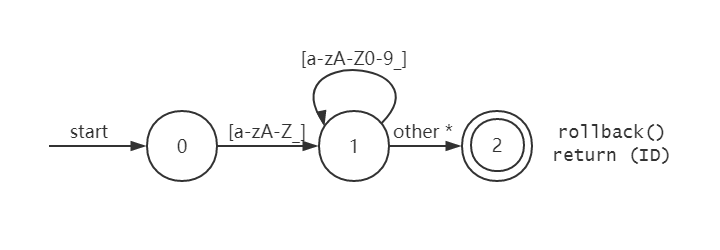
识别标识符
转移图
算法伪代码
|
|
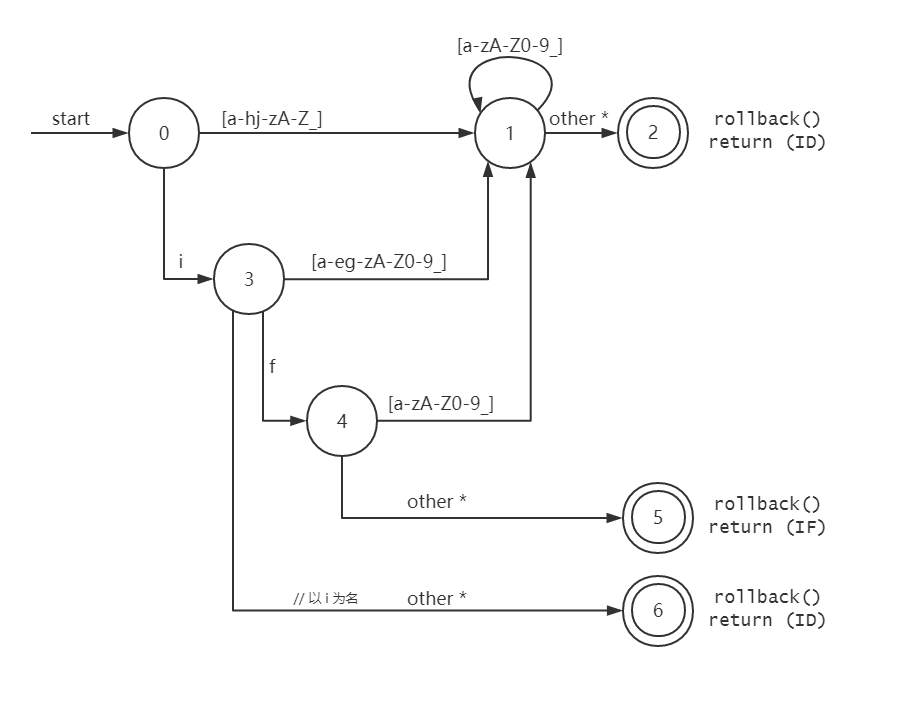
识别IF
在识别标识符的基础上,进一步实现识别特定的关键字。
转移图
算法伪代码
代码太长太麻烦,我不想写。
如果对所有关键字都要写这样特定的代码,工作量显然是相当巨大的,于是便有了关键字表算法。
关键字表算法
- 对所有关键字构造哈希表H
- 先统一按标识符的转移图来识别标识符
- 识别完成后,进一步查表H是否为关键字
通过合理的构造哈希表H(完美哈希),可以在O(1)时间完成。
课后作业
在这部分中,你将使用图转移算法手工实现一个小型的词法分析器。
- 分析器的输入:存储在文本文件中的字符序列,字符取自ASCII字符集。文件中可能包括四种记号:关键字if、符合C语言标准的标识符、空格符、回车符\n。
- 分析器的输出:打印出所识别的标识符的种类、及行号、列号信息。
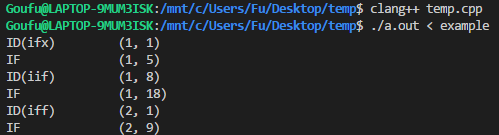
【示例】对于下面的文本文件:
ifx if iif if
iff if
你的输出应该是:
ID(ifx) (1, 1)
IF (1, 4)
ID(iif) (1, 8)
IF (1, 13)
ID(iff) (2, 1)
IF (2, 8)
我的代码(很恶心,但是不想改了):
输出效果: